NVIDIA stellt Nemotron-4 340B vor: Modelle für synthetische Datengenerierung
NVIDIA hat die Nemotron-4 340B-Familie vorgestellt, eine Serie von offenen Modellen, die Entwicklern ermöglicht, synthetische Daten für das Training großer Sprachmodelle (LLMs) in kommerziellen Anwendungen zu generieren. Diese Modelle sind für verschiedene Branchen wie Gesundheitswesen, Finanzen, Fertigung und Einzelhandel geeignet.
Bildquelle: Nvidia
Hohe Qualität der Trainingsdaten
Hochwertige Trainingsdaten sind entscheidend für die Leistung, Genauigkeit und Qualität der Antworten von maßgeschneiderten LLMs. Allerdings können robuste Datensätze teuer und schwer zugänglich sein. Mit der einzigartigen, offenen Modelllizenz von Nemotron-4 340B bietet NVIDIA Entwicklern eine kostenfreie und skalierbare Möglichkeit, synthetische Daten zu generieren und somit leistungsstarke LLMs zu erstellen.
Funktionsweise und Verfügbarkeit
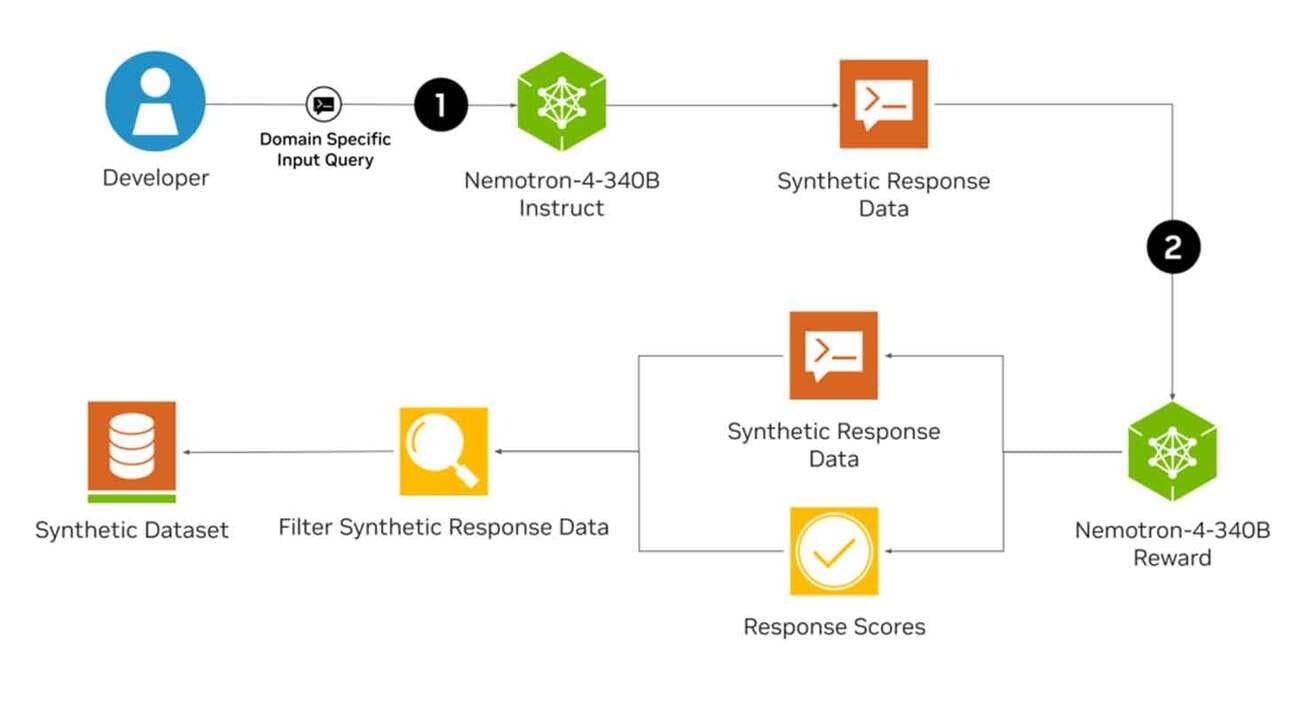
Die Nemotron-4 340B-Familie umfasst Basis-, Instruktions- und Bewertungsmodelle, die zusammen eine Pipeline zur Erzeugung synthetischer Daten bilden, die für das Training und die Verfeinerung von LLMs genutzt werden. Diese Modelle sind optimiert für NVIDIA NeMo, ein Open-Source-Framework für das End-to-End-Modelltraining, einschließlich Datenerstellung, Anpassung und Bewertung. Zudem sind sie für Inferenz mit der Open-Source-Bibliothek NVIDIA TensorRT-LLM optimiert.
Entwickler können Nemotron-4 340B ab sofort über Hugging Face herunterladen. Bald wird der Zugang auch über ai.nvidia.com möglich sein, wo die Modelle als NVIDIA NIM-Microservice mit einer standardisierten API bereitgestellt werden.
Generierung synthetischer Daten mit Nemotron-4 340B
Nemotron-4 340B Instruct erstellt diverse synthetische Daten, die die Merkmale realer Daten nachahmen und somit die Datenqualität verbessern, um die Leistung und Robustheit maßgeschneiderter LLMs in verschiedenen Bereichen zu erhöhen. Um die Qualität der KI-generierten Daten weiter zu steigern, können Entwickler das Nemotron-4 340B Reward-Modell verwenden, das Antworten auf fünf Attribute bewertet: Hilfreichkeit, Richtigkeit, Kohärenz, Komplexität und Redundanz.
Feinabstimmung mit NeMo und Optimierung für Inferenz mit TensorRT-LLM
Mit den Open-Source-Tools NVIDIA NeMo und NVIDIA TensorRT-LLM können Entwickler die Effizienz ihrer Instruktions- und Bewertungsmodelle zur Generierung synthetischer Daten und zur Bewertung von Antworten optimieren. Alle Nemotron-4 340B-Modelle sind mit TensorRT-LLM optimiert, um Tensor-Parallelismus zu nutzen, wodurch eine effiziente Inferenz im großen Maßstab ermöglicht wird.
Sicherheit und Zuverlässigkeit
Das Nemotron-4 340B Instruct-Modell hat umfangreiche Sicherheitstests, einschließlich adversarial Tests, durchlaufen und sich in vielen Risikobereichen gut bewährt. Benutzer sollten dennoch sorgfältige Bewertungen der Modellausgaben vornehmen, um sicherzustellen, dass die synthetisch generierten Daten für ihre Anwendungsfälle geeignet, sicher und genau sind.
Fazit
Mit Nemotron-4 340B stellt NVIDIA eine bahnbrechende Lösung für die synthetische Datengenerierung vor, die Entwicklern dabei hilft, leistungsstarke und präzise LLMs zu erstellen. Diese Modelle sind ein wesentlicher Schritt zur Demokratisierung der KI-Technologie und bieten flexible, skalierbare Lösungen für eine Vielzahl von Branchen.