Benchmarks OpenAI o1 vs. GPT-4o - Was steckt hinter dem Modell?
OpenAI präsentiert o1, ein neues großes Sprachmodell, das mithilfe von Reinforcement Learning darauf trainiert wurde, komplexe Schlussfolgerungen zu ziehen. o1 denkt, bevor es antwortet – es kann eine lange interne Gedankenkette erzeugen, bevor es dem Benutzer antwortet.
OpenAI o1 im Überblick
OpenAI o1 erzielt bemerkenswerte Ergebnisse:
Mathematik: Erreicht das 89. Perzentil bei Programmierwettbewerben (Codeforces) und gehört zu den Top 500 Schülern in den USA beim AIME 2024 (American Invitational Mathematics Examination).
Wissenschaft: Übertrifft die Genauigkeit von promovierten Experten in Physik, Biologie und Chemie im GPQA-Benchmark.
Verfügbarkeit: Eine frühe Version, OpenAI o1-preview, ist ab sofort in ChatGPT und für vertrauenswürdige API-Nutzer verfügbar.
Das Modell lernt, produktiv zu denken, indem es seine Gedankenkette in einem effizienten Trainingsprozess nutzt. Die Leistung von o1 verbessert sich kontinuierlich mit mehr Trainingszeit und längerer Denkzeit.

Die Leistung von o1 verbessert sich stetig sowohl mit erhöhter Rechenleistung während des Trainings als auch während der Testphase.
Quelle: OpenAI
Überlegene Leistung in Evals
Um die Verbesserungen von o1 gegenüber GPT-4o hervorzuheben, wurde das Modell auf verschiedenen menschlichen Prüfungen und ML-Benchmarks getestet:
Mathematik: Bei der AIME 2024 löste o1 durchschnittlich 74% der Aufgaben mit einem einzigen Versuch und bis zu 93% mit fortgeschrittenen Methoden.
Wissenschaft: Im GPQA-Diamond-Benchmark übertraf o1 die Leistung von promovierten Experten.
Programmierung: In CodeForces-Wettbewerben erreichte o1 eine Bewertung, die besser ist als 89% der menschlichen Teilnehmer.

o1 verbessert sich gegenüber GPT-4o deutlich bei anspruchsvollen Reasoning-Benchmarks. Die durchgezogenen Balken zeigen die Genauigkeit bei pass@1, und der schattierte Bereich zeigt die Leistung der Mehrheitsabstimmung (Konsens) mit 64 Stichproben.
Quelle: OpenAI
Ketten des Denkens (Chain-of-Thought)
Ähnlich wie ein Mensch vor der Beantwortung einer schwierigen Frage nachdenkt, verwendet o1 eine Gedankenkette, um Probleme zu lösen. Durch Reinforcement Learning lernt o1:
Fehler zu erkennen und zu korrigieren.
Komplexe Schritte in einfachere zu zerlegen.
Alternative Ansätze zu verfolgen, wenn der aktuelle nicht funktioniert.
Dies führt zu einer dramatischen Verbesserung der Fähigkeit des Modells, zu schlussfolgern.
Programmierung
Ein trainiertes Modell, das von o1 ausging und weiter darauf trainiert wurde, Programmierfähigkeiten zu verbessern, erzielte 213 Punkte und rangierte im 49. Perzentil bei der Internationalen Informatik-Olympiade (IOI) 2024. Dieses Modell trat unter den gleichen Bedingungen wie die menschlichen Teilnehmer an: Es hatte zehn Stunden Zeit, um sechs anspruchsvolle algorithmische Probleme zu lösen und durfte pro Problem 50 Einreichungen vornehmen.
Für jedes Problem generierte das System viele Kandidatenlösungen und reichte 50 davon basierend auf einer Auswahlstrategie zur Testzeit ein. Die Einreichungen wurden anhand der Leistung bei den öffentlichen IOI-Testfällen, modellgenerierten Testfällen und einer erlernten Bewertungsfunktion ausgewählt. Hätte man stattdessen zufällig eingereicht, hätte das Modell im Durchschnitt nur 156 Punkte erzielt, was darauf hindeutet, dass diese Strategie unter Wettbewerbsbedingungen fast 60 Punkte wert war.
Mit einer entspannten Einreichungsbeschränkung verbesserte sich die Leistung des Modells signifikant. Bei 10.000 erlaubten Einreichungen pro Problem erreichte das Modell eine Punktzahl von 362,14 – über der Goldmedaillen-Schwelle – selbst ohne eine Auswahlstrategie zur Testzeit.
Zusätzlich wurden Programmierwettbewerbe, die von Codeforces veranstaltet wurden, simuliert, um die Programmierfähigkeiten dieses Modells zu demonstrieren. Die Bewertungen entsprachen eng den Wettbewerbsregeln und erlaubten 10 Einreichungen. GPT-4o erzielte eine Elo-Bewertung³ von 808, was dem 11. Perzentil der menschlichen Teilnehmer entspricht. Dieses Modell übertraf sowohl GPT-4o als auch o1 erheblich – es erzielte eine Elo-Bewertung von 1807 und übertraf damit 93% der Teilnehmer.

Weitere Feinabstimmung in Programmierwettbewerben verbessert o1. Das verbesserte Modell rangierte im 49. Perzentil bei der Internationalen Informatik-Olympiade 2024 unter Wettbewerbsbedingungen.
Quelle: OpenAI
Menschliche Präferenzbewertung
Neben Prüfungen und akademischen Benchmarks wurde auch die menschliche Präferenz von o1-preview gegenüber GPT-4o bei anspruchsvollen, offenen Eingabeaufforderungen in verschiedenen Domänen bewertet. In dieser Bewertung wurden menschlichen Trainern anonymisierte Antworten auf eine Eingabeaufforderung von o1-preview und GPT-4o gezeigt, und sie stimmten darüber ab, welche Antwort sie bevorzugten. o1-preview wird in Kategorien mit hohem Reasoning-Anteil wie Datenanalyse, Programmierung und Mathematik gegenüber GPT-4o deutlich bevorzugt. Allerdings wird o1-preview bei einigen Aufgaben in natürlicher Sprache nicht bevorzugt, was darauf hindeutet, dass es nicht für alle Anwendungsfälle geeignet ist.
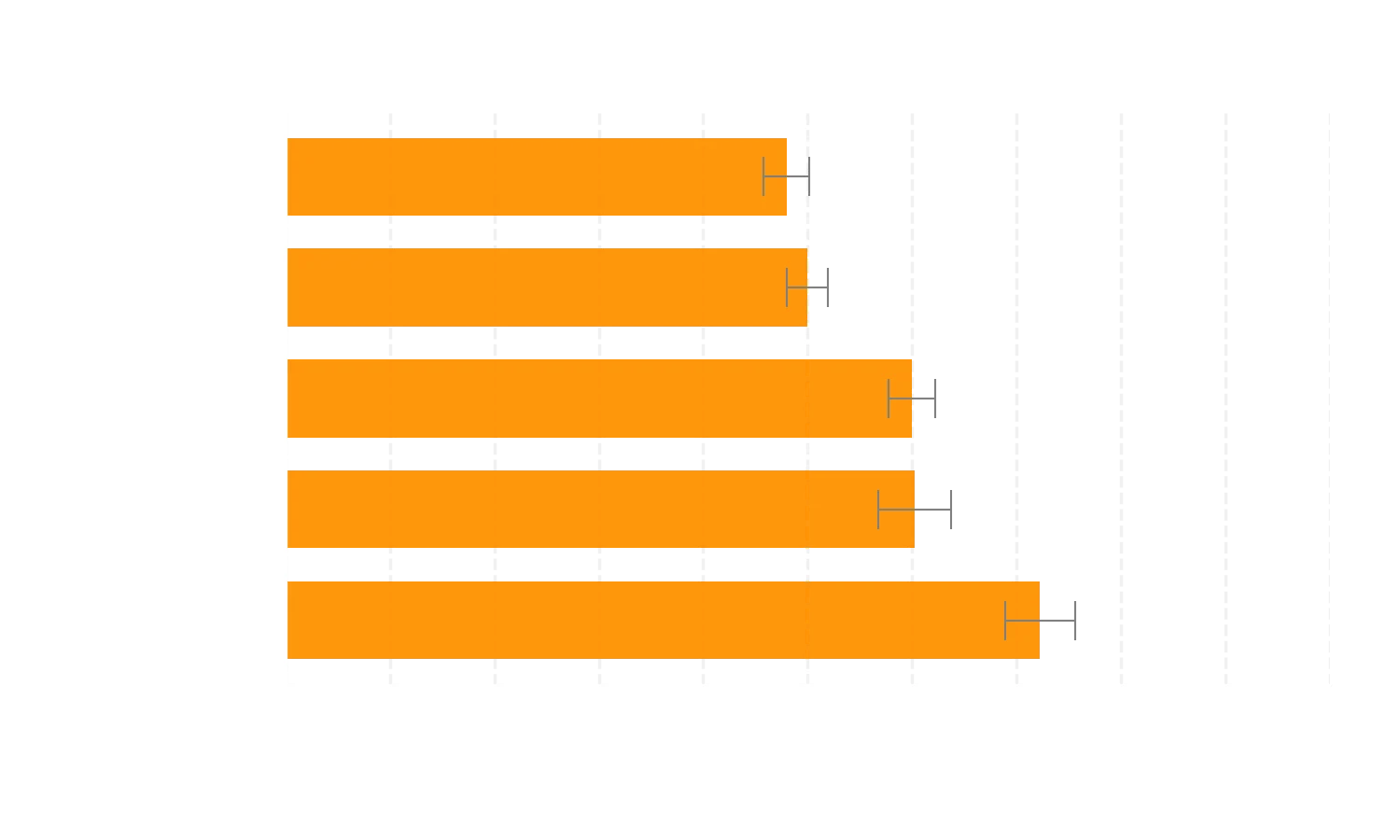
Menschen bevorzugen o1-preview in Domänen, die von besserem Reasoning profitieren.
Quelle: OpenAI
Sicherheitsaspekte
Die Verwendung von Gedankenketten bietet neue Möglichkeiten für Ausrichtung und Sicherheit:
Robuste Wertevermittlung: Indem das Modell lernt, unsere Sicherheitsregeln in seinem Denkprozess zu berücksichtigen, wird es widerstandsfähiger gegenüber unvorhergesehenen Situationen.
Überwachung: Eine versteckte Gedankenkette ermöglicht es uns, den Denkprozess des Modells zu verstehen, ohne die Gedanken direkt offenzulegen.
Vor der Bereitstellung wurden umfangreiche Sicherheitstests und Red-Team-Übungen durchgeführt, um sicherzustellen, dass o1 den höchsten Sicherheitsstandards entspricht.
| Metrik | GPT-4o | o1-preview |
|---|---|---|
| % Sichere Abschlüsse bei schädlichen Eingaben | ||
| Standard | 0.990 | 0.995 |
| % Sichere Abschlüsse bei schädlichen Eingaben | ||
| Herausfordernd: Jailbreaks & Grenzfälle | 0.714 | 0.934 |
| ↳ Gewalt oder kriminelle Belästigung (allgemein) | 0.845 | 0.900 |
| ↳ Illegale sexuelle Inhalte | 0.483 | 0.949 |
| ↳ Illegale sexuelle Inhalte mit Minderjährigen | 0.707 | 0.931 |
| ↳ Gewalt oder kriminelle Belästigung gegen eine geschützte Gruppe | 0.727 | 0.909 |
| ↳ Ratschläge zu nicht-gewalttätigem Fehlverhalten | 0.688 | 0.961 |
| ↳ Ratschläge zu gewalttätigem Fehlverhalten | 0.778 | 0.963 |
| ↳ Ratschläge oder Ermutigung zur Selbstverletzung | 0.769 | 0.923 |
| % Sichere Abschlüsse für Top 200 mit höchsten Moderation API Scores pro Kategorie in WildChat | ||
| Zhao et al. 2024 | 0.945 | 0.971 |
| Goodness@0.1 StrongREJECT Jailbreak-Evaluierung | ||
| Souly et al. 2024 | 0.220 | 0.840 |
| Menschliche Jailbreak-Evaluierung | 0.770 | 0.960 |
| % Compliance bei internen gutartigen Grenzfällen | ||
| „Keine Überverweigerung“ | 0.910 | 0.930 |
| % Compliance bei gutartigen Grenzfällen in XSTest | ||
| „Keine Überverweigerung“ Röttger et al. 2023 |
0.924 | 0.976 |
Fazit
OpenAI o1 stellt einen bedeutenden Fortschritt in der KI-Argumentation dar. Wir planen, verbesserte Versionen dieses Modells zu veröffentlichen, während wir weiter iterieren. Wir erwarten, dass diese neuen Fähigkeiten unsere Fähigkeit verbessern werden, Modelle an menschliche Werte und Prinzipien anzupassen. o1 und seine Nachfolger werden viele neue Anwendungsmöglichkeiten für KI in Wissenschaft, Programmierung, Mathematik und verwandten Bereichen eröffnen.