Codestral Mamba bringt Effizienz in die Modellarchitektur
Die Veröffentlichung von Codestral Mamba markiert einen bedeutenden Schritt in der Erforschung neuer Modellarchitekturen. Entwickelt mit Unterstützung von Albert Gu und Tri Dao, bietet Mamba beeindruckende Vorteile gegenüber herkömmlichen Transformer-Modellen.
Bildquelle: Mistral AI
Codestral Mamba wurde mit dem Ziel entwickelt, lineare Zeitinferenz und die theoretische Fähigkeit zur Modellierung unendlicher Sequenzen zu ermöglichen. Diese Eigenschaften machen das Modell besonders nützlich für Anwendungsfälle, die hohe Codeproduktivität erfordern. Die Effizienz von Mamba zeigt sich besonders bei der Verarbeitung langer Eingaben, wobei schnelle Reaktionszeiten garantiert sind.
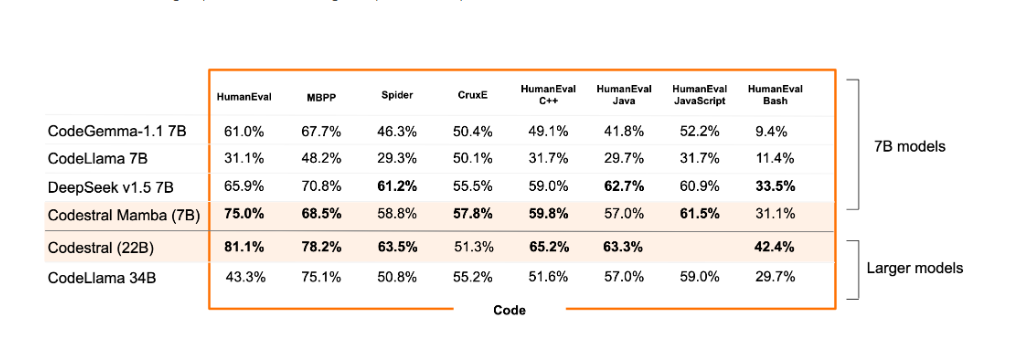
Die Benchmark-Tests von Codestral Mamba haben beeindruckende Ergebnisse gezeigt, insbesondere bei der kontextbezogenen Abfrage bis zu 256k Token. Dies unterstreicht das Potenzial von Mamba als lokaler Code-Assistent.
Du kannst Codestral Mamba über das mistral-inference SDK einsetzen, das auf den Referenzimplementierungen aus dem GitHub-Repository von Mamba basiert. Alternativ ist eine Bereitstellung über TensorRT-LLM möglich, und für lokale Inferenz wird bald Unterstützung in llama.cpp erwartet. Die Rohdaten des Modells sind über HuggingFace verfügbar.
Für einfache Tests ist Codestral Mamba auf der Plattform (codestral-mamba-2407) verfügbar, zusammen mit Codestral 22B. Während Codestral Mamba unter der Apache 2.0-Lizenz erhältlich ist, ist Codestral 22B entweder unter einer kommerziellen Lizenz für den Eigenbetrieb oder unter einer Community-Lizenz für Testzwecke verfügbar.
Codestral Mamba repräsentiert eine bahnbrechende Entwicklung in der Modellarchitektur und bietet eine leistungsstarke, effiziente Lösung für komplexe Anwendungsfälle in der Codeproduktion.